OpenRelik Design
Author: Johan Berggren
Published: Sep 2024
Document version: 1.0
Status: Final
Discussion forum for this design document can be found here: https://github.com/orgs/openrelik/discussions/5
Objective
Build an open-source, artifact centric, distributed system for processing and analyzing digital forensic artifacts. Create a collaborative environment where investigators and analysts can efficiently share artifacts, design processing pipelines, and streamline analysis workflows.
Background
Digital forensics faces challenges like fragmented data, complex workflows, tool dependencies and collaboration needs. OpenRelik addresses these by organizing data, streamlining workflows, enabling collaboration, and offering scalability and extensibility.
Challenges in Digital Forensics
Data Fragmentation and Silos: Evidence is often scattered across various sources. OpenRelik aims to improve data management and collaboration by centralizing the storage and processing of digital forensic artifacts.
Workflow Efficiency: Forensic analysis often involves intricate workflows. OpenRelik streamlines these processes, offering a user-friendly interface for designing and executing complex pipelines.
Collaboration: Effective teamwork is critical for successful investigations. OpenRelik enables collaboration through features for sharing artifacts, workflows, and results.
Scalability: Digital evidence is growing and becoming more complex. OpenRelik’s scalable architecture supports efficient processing and analysis of large datasets, including those stored in the cloud.
Developer Friendly: OpenRelik promotes extensibility through decoupled workers with minimal dependencies. This allows developers to create and integrate new processing capabilities independently from the core system.
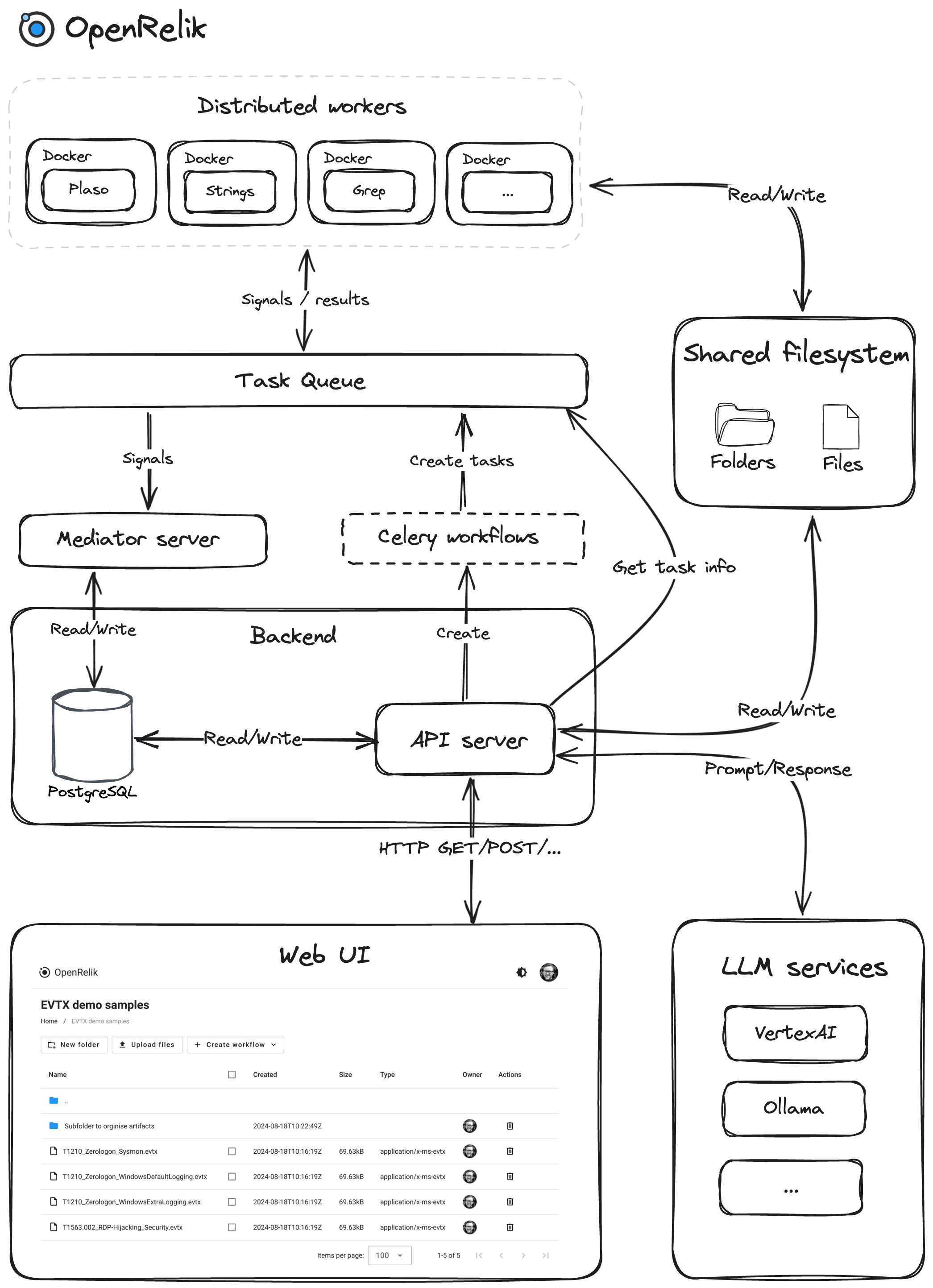
Architectural components
RESTful API Server (FastAPI): Central coordinator for handling user requests, managing workflow execution, and providing system status updates. It acts as the communication bridge between the user interface and the backend components.
SQL Database: Relational database (PostgreSQL) for storing structured information about the system, including details about files, folders, workflows, user accounts, and other critical system entities. It ensures data integrity and provides efficient querying capabilities.
Shared File System: Centralized storage system enabling seamless data sharing and access across all components. It serves as the repository for artifacts, workflow results, and other essential files. Examples: NFS for on-premise or GCP Filestore for Cloud deployments.
Authorization: Fine grained control over authorization for files, folders and workflows. Ability to set access to public, shared and private for individual items.
Workflow Engine: Using the open-source workflow execution engine (Celery) for orchestrating complex workflows. It breaks down workflows into individual tasks, distributes them across available workers, and manages their dependencies and execution order.
Task Queue: Message broker for the workflow engine. It stores tasks in queues, allowing workers to efficiently execute them in a distributed manner.
Workers: Distributed independent processing units that execute tasks assigned by the Celery workflow engine. They can run on different machines and are always containerized, providing scalability and fault tolerance.
Mediator Server: Facilitates communication between workers and the core system, managing signals and task results.
Cloud Support: Enables attachment and access to cloud-native block devices for processing, allowing seamless integration with cloud storage solutions.
Artifact Extraction: Supports extracting artifacts from disk images and block devices using Artifact definitions, enabling targeted data extraction for further analysis.
Web Interface: Intuitive web interface for interacting with the system, creating workflows, and visualizing results.
LLM Services: Integration with Large Language Models (LLMs) for extended analysis capabilities.
Endpoint Services: Supports artifact collection using external endpoint agents, allowing centralized collection and analysis of security-related data from various devices.
Guiding principles
Scalability and Flexibility: The system should be designed to handle increasing workloads and accommodate future growth. It should support horizontal scaling of workers and seamless integration with cloud resources to adapt to changing demands.
Modularity and Extensibility: The system’s components should be loosely coupled and modular, allowing for easy maintenance, updates, and the addition of new features or analysis capabilities. Workers should be developed independently from the core system, making it quick and easy to add new processing functionality. Additionally, worker dependencies are managed in a containerized environment, providing isolation, portability, and consistency across different deployment environments.
Efficiency and Performance: The system should prioritize efficient resource utilization and task execution to ensure optimal performance and responsiveness, even under heavy workloads.
Data Integrity and Security: The system should implement robust mechanisms to protect data integrity and confidentiality. It should adhere to security best practices and ensure proper access controls. Audit logs for actions taken on artifacts and other items such as files, folders, workflows. Ability to trace what actions have been taken for a specific artifact, and if it is a result of a workflow, the user should be able to know how the artifact was derived and from where.
User-Centric Collaboration: Provide an intuitive interface for easy workflow creation, management, and result visualization. Facilitate team collaboration by sharing artifacts, workflows and results.
Detailed design
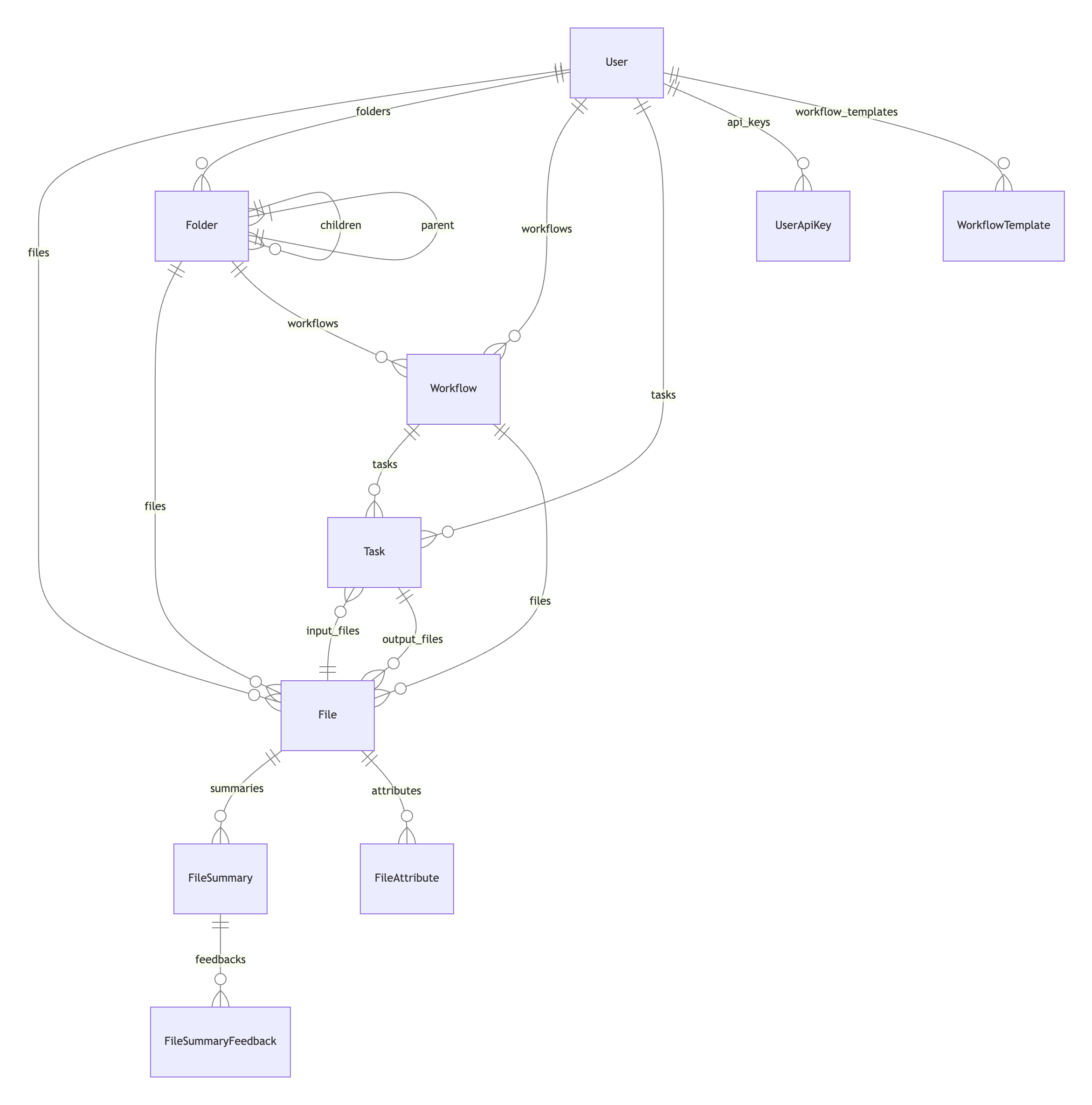
Data model
The system’s data model is designed to efficiently store and manage information related to files, folders, users, workflows, and tasks, facilitating seamless data organization, analysis, and retrieval.
Core Entities:
File: Represents individual files within the system, storing metadata like filename, size, hashes, and relationships to folders, workflows, and tasks.
Folder: Organizes files into a hierarchical structure, capturing metadata like folder name, description, and relationships to parent folders and child folders.
User: Stores user information such as name, email, and preferences, and maintains relationships with folders, files, workflows, and tasks associated with the user.
Workflow: Defines a sequence of tasks for processing data, capturing details like workflow name, description, and associated tasks and files.
Task: Represents individual processing steps within a workflow, storing configuration, status, results, and relationships to input and output files.
Relationships:
- File-Folder: Files belong to folders, creating a hierarchical structure.
- User-File/Folder/Workflow/Task: Users own files, folders, workflows, and tasks.
- Workflow-Task: Workflows are composed of multiple tasks.
- Task-File: Tasks have input and output files, enabling data flow through the workflow.
Additional Features:
- File Summaries & Feedback: Stores summaries and user feedback for files.
- File and Folder Attributes: Allows flexible addition of metadata to files and folders.
- User API Keys: Manages secure access for users interacting with the system through APIs.
- Workflow Templates: Provides reusable workflow structures for common processing scenarios.
This data model, implemented using SQLAlchemy, provides a robust foundation for data management within the system, ensuring efficient storage, retrieval, and analysis of information crucial for effective workflow execution and artifact processing.
API server
The API server will be built using OpenAPI. OpenAPI (formerly known as Swagger) is a well established specification for describing RESTful APIs in a machine-readable format. It facilitates capabilities to automatically generate clients for various programming languages and automatically create rich API documentation. We will use FastAPI, a modern and efficient Python API framework for RESTful APIs. The API server will serve as the central communication hub for the system, handling various requests related to files, folders, workflows, and user management. It will provide a structured and well-defined interface for interacting with the system’s core functionalities.
Key Features:
File Management:
- Retrieve file metadata and content.
- Download files directly or as a stream.
- Upload new files and initiate background hash generation.
- Create cloud disk files by storing connection details.
- Delete files.
- Retrieve associated workflows and tasks.
- Generate and manage file summaries.
Folder Management:
- Retrieve root folders and subfolders.
- Create, update, and delete folders.
- Retrieve files and workflows within a folder.
User Management:
- Retrieve current user information.
- Manage API keys for secure access.
Workflow Management:
- Retrieve, create, update, copy, and delete workflows.
- Execute workflows by submitting them to the Celery engine.
- Retrieve registered Celery tasks.
- Create workflow templates from existing workflows.
Implementation Goals:
RESTful Architecture: Adhere to standard HTTP methods (GET, POST, PATCH, DELETE) to interact with resources, ensuring a clear and consistent API design.
Asynchronous Operations: Utilize background tasks for time-consuming operations like hash generation and summary creation, improving responsiveness.
Data Validation: Incorporate input validation to ensure data integrity and prevent errors.
Error Handling: Include mechanisms to gracefully handle exceptions and provide informative error messages.
Security: Implement user authentication and authorization to protect sensitive data and operations.
Integration with Core Components: Seamlessly interact with the database, Celery workflow engine, and shared file system to manage and process data.
Mediator server
The mediator server will play an important role in orchestrating communication and data flow between the distributed workers and the core system components. It will function as a central point for receiving task-related signals from workers, updating the system’s database accordingly, and ensuring data consistency and synchronization.
Core Responsibilities:
Celery Event Monitoring: Actively monitors Celery task events, capturing real-time updates on task progress, completion, and potential errors.
Event Handling: Processes task-related events, updating task status and progress in the database, extracting results upon successful completion, and logging exceptions and tracebacks in case of failures.
Database Interaction: Seamlessly interacts with the database, utilizing dedicated functions to retrieve and update task-related information.
Data Synchronization: Ensures data consistency across the system by updating the database with the latest information from the workers, providing accurate and up-to-date insights into workflow execution.
Implementation Goals:
Efficient Communication: Establish a reliable and low-latency communication channel with workers to enable real-time updates and efficient event handling.
Robust Error Handling: Implement robust error handling mechanisms to gracefully manage task failures and provide informative error messages for troubleshooting.
Data Integrity: Maintain data integrity by ensuring accurate and consistent updates to the database, reflecting the actual state of task execution.
Implementation Language:
- The mediator server will be written in Python, leveraging libraries and frameworks like Celery for task management and SQLAlchemy for database interaction. This choice enables seamless integration with the FastAPI-based API server and efficient communication with the other core components.
Shared file system
OpenRelik requires a shared filesystem to provide centralized storage and access to data across all system components.
Functional Requirements
- Hard link support: The filesystem must support the creation and management of hard links, enabling efficient data copying and versioning without unnecessary duplication.
- Concurrent access: The filesystem must handle concurrent read and write operations from multiple workers and system components, ensuring data integrity and optimal performance.
- Scalability: The filesystem should be scalable to accommodate growing data volumes and increased workloads as the system expands.
- Accessibility: The filesystem must be readily accessible from all OpenRelik components, regardless of their deployment environment (on-premise or cloud).
Non-functional Requirements
- Performance: The filesystem should deliver adequate performance to support efficient data access and processing by multiple workers and system components concurrently.
- Reliability: The filesystem should be reliable and fault-tolerant, minimizing the risk of data loss or corruption.
- Security: The filesystem should implement appropriate security measures to protect sensitive data from unauthorized access or modification.
OpenRelik is compatible with the following shared file systems that meet the above requirements:
- Network File System (NFS)
- Google Cloud Filestore
The choice of filesystem will depend on the specific deployment environment and organizational requirements.
Cloud Integration
The system is designed to work seamlessly with cloud environments and access to cloud native disks:
Cloud Storage Connectivity: Direct integration with cloud storage enables users to easily attach and access cloud-native block devices. This eliminates the need for complex data transfers and facilitates streamlined workflows directly within the cloud environment.
Block Device Support: The ability to work with cloud-native block devices offers efficient and scalable processing of data stored in the cloud. This allows users to seamless access to cloud storage while benefiting from the system’s processing capabilities.
Seamless Workflow Integration: With seamless integrating with cloud solutions, the system lets users build end-to-end workflows that span both traditional disk images and cloud native disks.
Workers and Tasks
Task Execution workflow:
- The worker receives input files and metadata from the Celery task queue.
- It dynamically constructs the required command based on the input and task metadata.
- The worker executes the command, securely capturing and managing both standard output and standard error streams.
- The generated output is persistently stored, and its file paths are recorded.
- If no output is produced, the worker raises an exception to flag the potential error condition.
- The worker returns a structured dictionary containing essential information such as output file locations, the associated workflow ID, the executed command itself, and the original task metadata.
Task Registration and Metadata Usage:
- The function responsible for executing external commands is registered as a Celery task, complete with comprehensive metadata.
- This metadata serves a multifaceted role, encompassing task identification, seamless API server registration, and effective rendering within the Web UI.
- Furthermore, the metadata plays an important role in facilitating various aspects of task management, including configuration, dependency resolution, and error handling.
Interaction with Mediator Server:
- Upon successful task completion or encountering an error, the worker promptly sends a Celery signal to the designated mediator server.
- This signal encapsulates critical information such as the task ID, the computed result or error details, and contextual data.
Workflows
The system will allow users to create complex data processing pipelines by connecting multiple tasks together. These tasks will be linked in a sequence, where the output of one task will become the input for the next, ensuring a smooth and logical flow of data.
Workflow collaboration and remix:
- The system will allow users to share workflows as templates making it easy to bootstrap new investigations. Just select a template and the workflow will be pre-built and ready to be customized or executed on the selected artifacts. Users can also quickly copy and remix an existing workflow.
Parallel Task Execution:
- The system will support the simultaneous execution of multiple tasks within a workflow. This feature will enhance efficiency by utilizing available resources and reducing overall processing time, especially when tasks are independent of each other.
Flexibility and Adaptability:
- The ability to chain tasks sequentially and execute them in parallel will offer flexibility in workflow design. Users will be able to customize workflows to meet their specific data processing needs, optimizing both efficiency and accuracy.
Workflow constructs:
Chain: Tasks are executed in a linear sequence. The output of one task serves as the input for the subsequent task (pipeline).
Group: Tasks are executed concurrently (in parallel). Each task receives the same input from the preceding task. This construct is beneficial when multiple independent tools need to process the same set of data or artifacts. A task within a Group can itself be a Chain of tasks.
Chord: Similar to a Group, tasks are executed in parallel. However, the outputs of all tasks in the Chord are consolidated into a single result and then passed to a designated “callback” task for further processing. This is useful when you need to run a tool in parallel on multiple input artifacts and then perform a unified action on the collective results. For instance, if you have 10 files that need individual processing with the same tool, a Chord can split these into parallel tasks and then consolidate the results for subsequent analysis or action.
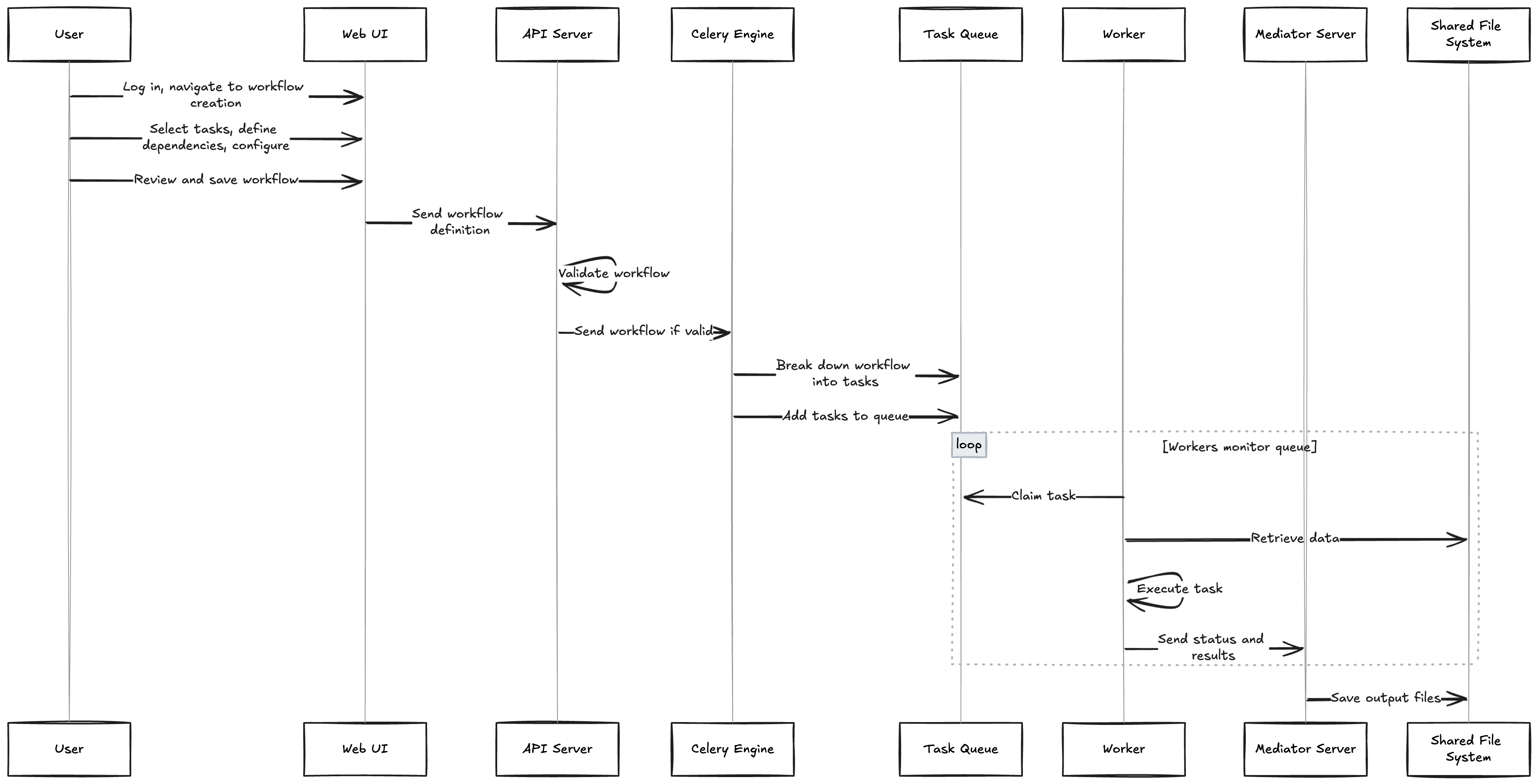
Life of a Workflow - A user journey
As a forensic analyst, I want to create and execute complex workflows to analyze data efficiently and accurately.
Workflow Design (User Interface):
- User logs into the OpenRelik web interface and navigates to the workflow creation page.
- They select the desired input file(s).
- They select the desired processing actions from a list of available tasks.
- The user specifies the order in which tasks should be executed, establishing dependencies between them.
- Some tasks might offer additional configuration options for customization.
- Once the workflow is designed, the user reviews and saves it.
Workflow Validation and Execution (API Server):
- Upon saving the workflow, the web interface sends the workflow definition, including task sequences and configurations, to the API server.
- The API server validates the workflow, checking for correctness and ensuring dependencies are met.
- If valid, the API server sends the workflow to the Celery workflow engine for execution.
Task Queuing (Task Queue):
- The Celery engine breaks down the workflow into individual tasks and adds them to the Redis task queue.
- Each task is assigned a unique ID and carries its dependencies and configuration details.
Task Execution (Distributed Workers):
- Workers continuously check the task queue for available tasks.
- A worker claiming a task retrieves the required artifact data from the shared file system.
- The worker executes the task’s processing steps, applying any provided configuration.
- Upon task completion, the worker signals the mediator server with its status and results.
Sharing and Access Control
The system offers a flexible and granular approach to managing access and permissions for various elements within the platform:
Fine-Grained Control: Users have precise control over who can view, edit, or interact with specific files and folders. This level of granularity allows for tailored sharing and collaboration scenarios.
Access Levels:
- Public: Content is accessible to anyone, even without an account.
- Shared: Content is shared with specific individuals or groups, who may have varying levels of permission (view-only, edit, etc.).
- Private: Content is restricted to the owner or designated administrators.
Artifact Extraction
The system streamlines the process of extracting information from disk images and block devices through the utilization of Artifact Definitions. The system will use the open-source project ForensicArtifacts.
Targeted Extraction: Artifact Definitions enable users to precisely specify the files or other relevant artifacts they seek to extract. These definitions can include file paths, registry keys, and other identifying characteristics.
Efficient Analysis: By leveraging Artifact Definitions, the system intelligently identifies and extracts only the desired artifacts, eliminating the need for manual searching and sifting through large volumes of data. This focused extraction process expedites analysis and investigation workflows.
LLM services
The system will extend its analysis capabilities through seamless integration with Large Language Models (LLMs).
Plugin-Based Access: A plugin architecture will enable flexible access to various LLM providers, allowing users to choose the best-suited model for their specific needs and preferences.
Local LLM Support: The system will also support local deployment of models as a self hosted alternative. The system will use the open-source Ollama runtime to deploy open models.
Endpoint Services
The system will support artifact collection using external endpoint agents, enabling centralized collection and analysis of security-related data from various devices.
Isolated Containers: Each supported endpoint product will operate within its own isolated container, ensuring stability and preventing conflicts. This enables developers to add support for different providers and maintain them outside of the OpenRelik core system.
Simplified Interface: The system will provide a simplified interface for interacting with endpoint agents. Key functionalities will include:
- List Endpoints: Easily view and manage connected endpoints.
- Collect Artifacts (Single Endpoint): Initiate artifact collection from a specific endpoint.
- Fleet Collection: Efficiently collect artifacts from multiple endpoints simultaneously.
Web user-interface
The Web UI, developed with Vue3 and incorporating Material Design principles, will serve as the primary interface for users to interact with the system. It will provide an intuitive and user-centric experience for managing files, folders, workflows, and tasks.
Key Features:
File and Folder Management:
- Visually navigate through folders and files.
- Upload, download, and delete files.
- Create, rename, and delete folders.
- View file details and metadata.
Workflow Management:
- Create, edit, and visualize workflows using an interface with a clear and intuitive layout.
- Configure task dependencies and parameters.
- Execute workflows and monitor their progress in real-time.
- View and analyze workflow results.
Collaboration Features:
- Share files and folders with other users.
- Collaboratively create and edit workflows.
- Comment and discuss files and workflows.
UI design Principles:
Intuitive User Experience: The interface will be designed to be easy to understand and navigate
Visual Clarity: Clear and concise visual elements will be used to present information, making it easy for users to find what they need.
Collaboration: The UI will facilitate collaboration among team members, enabling them to work together on files and workflows seamlessly.
User-Centric Design: The interface will be tailored to the needs of the users, prioritizing usability and efficiency.
Technology Stack:
Vue3: A modern JavaScript framework for building user interfaces, chosen for its flexibility and ease of use.
Material Design: A design system that provides a consistent and visually appealing look and feel, enhancing the user experience.
Deployment Options
OpenRelik is designed to be flexible, giving you the freedom to choose the self-hosted deployment option that best suits your needs and infrastructure:
Single Server (or laptop):
- Great for testing, evaluation, or smaller-scale investigations.
- Easy to set up and get started quickly on a single machine.
- Perfect for individual users or smaller teams with limited resources.
Self-Hosted on-premise:
- Ideal for organizations that require full control over their data and infrastructure.
- Set it up and manage it on your own servers within your own data center.
Self-Hosted in the Cloud:
- Perfect for teams looking for quick setup and scalability.
- Deploy and manage OpenRelik on cloud infrastructure of your choice.
- Reduces the need for on-premise infrastructure and maintenance.
- Utilize Kubernetes via Helm chart deployment.